publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
- ACL
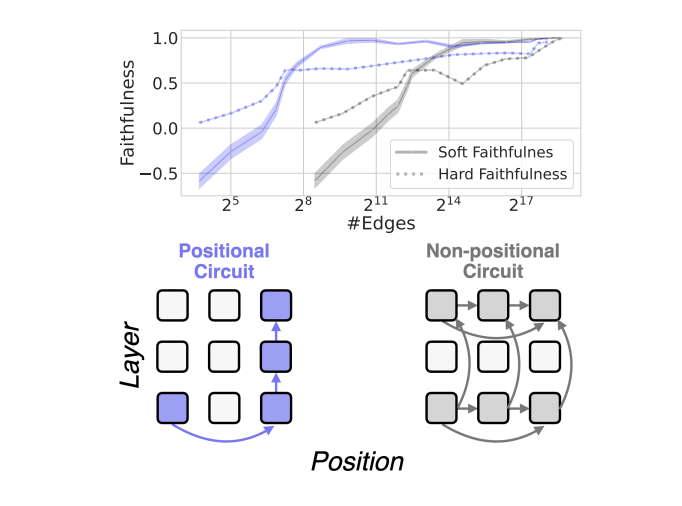 Position-aware Automatic Circuit DiscoveryTal Haklay, Hadas Orgad, David Bau, and 2 more authorsCoRR, 2025
Position-aware Automatic Circuit DiscoveryTal Haklay, Hadas Orgad, David Bau, and 2 more authorsCoRR, 2025A widely used strategy to discover and understand language model mechanisms is circuit analysis. A circuit is a minimal subgraph of a model’s computation graph that executes a specific task. We identify a gap in existing circuit discovery methods: they assume circuits are position-invariant, treating model components as equally relevant across input positions. This limits their ability to capture cross-positional interactions or mechanisms that vary across positions. To address this gap, we propose two improvements to incorporate positionality into circuits, even on tasks containing variable-length examples. First, we extend edge attribution patching, a gradient-based method for circuit discovery, to differentiate between token positions. Second, we introduce the concept of a dataset schema, which defines token spans with similar semantics across examples, enabling position-aware circuit discovery in datasets with variable length examples. We additionally develop an automated pipeline for schema generation and application using large language models. Our approach enables fully automated discovery of position-sensitive circuits, yielding better trade-offs between circuit size and faithfulness compared to prior work.
@article{DBLP:journals/corr/abs-2502-04577, author = {Haklay, Tal and Orgad, Hadas and Bau, David and Mueller, Aaron and Belinkov, Yonatan}, title = {Position-aware Automatic Circuit Discovery}, journal = {CoRR}, volume = {abs/2502.04577}, year = {2025}, url = {https://doi.org/10.48550/arXiv.2502.04577}, eprinttype = {arXiv}, eprint = {2502.04577}, timestamp = {Wed, 12 Mar 2025 22:47:55 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-2502-04577.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, } - ICML
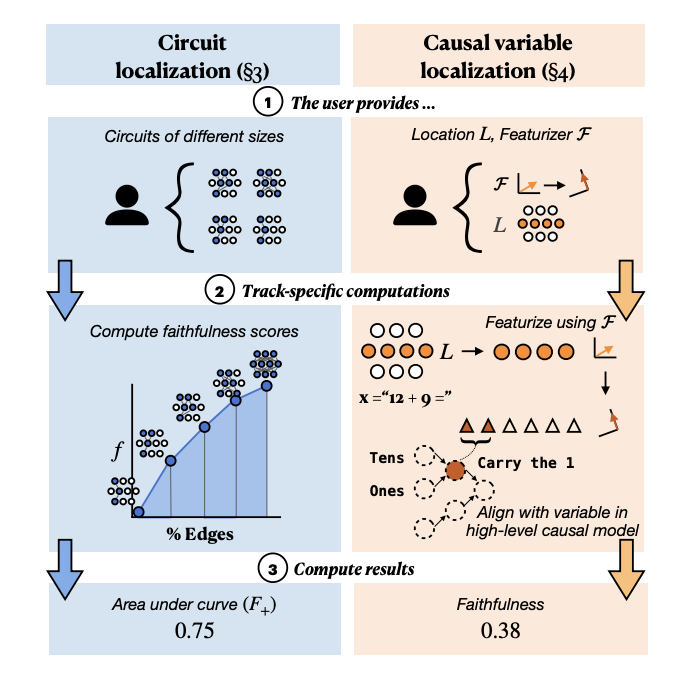 MIB: A Mechanistic Interpretability BenchmarkAaron Mueller, Atticus Geiger, Sarah Wiegreffe, and 20 more authorsCoRR, 2025
MIB: A Mechanistic Interpretability BenchmarkAaron Mueller, Atticus Geiger, Sarah Wiegreffe, and 20 more authorsCoRR, 2025How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
@article{DBLP:journals/corr/abs-2504-13151, author = {Mueller, Aaron and Geiger, Atticus and Wiegreffe, Sarah and Arad, Dana and Arcuschin, Iv{\'{a}}n and Belfki, Adam and Chan, Yik Siu and Fiotto{-}Kaufman, Jaden and Haklay, Tal and Hanna, Michael and Huang, Jing and Gupta, Rohan and Nikankin, Yaniv and Orgad, Hadas and Prakash, Nikhil and Reusch, Anja and Sankaranarayanan, Aruna and Shao, Shun and Stolfo, Alessandro and Tutek, Martin and Zur, Amir and Bau, David and Belinkov, Yonatan}, title = {{MIB:} {A} Mechanistic Interpretability Benchmark}, journal = {CoRR}, volume = {abs/2504.13151}, year = {2025}, url = {https://doi.org/10.48550/arXiv.2504.13151}, eprinttype = {arXiv}, eprint = {2504.13151}, timestamp = {Thu, 22 May 2025 21:00:35 +0200}, biburl = {https://dblp.org/rec/journals/corr/abs-2504-13151.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, }
2024
- ICLR
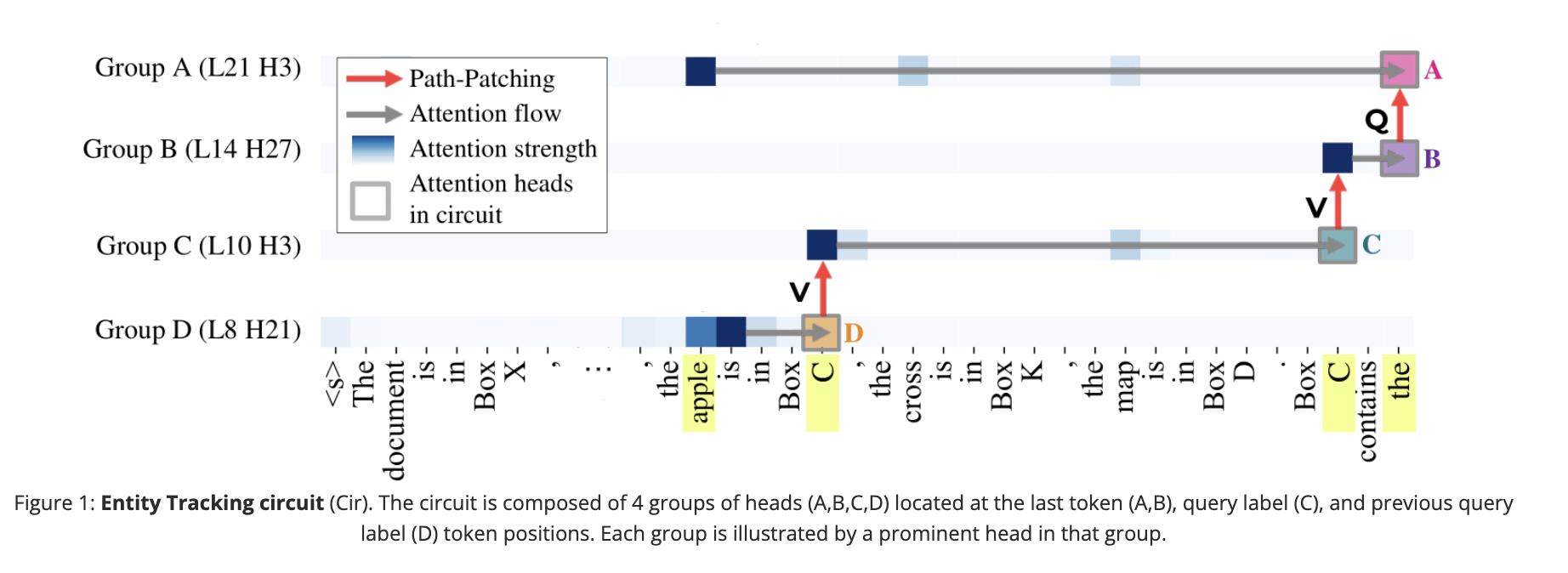 Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity TrackingNikhil Prakash, Tamar Rott Shaham, Tal Haklay, and 2 more authorsIn The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity TrackingNikhil Prakash, Tamar Rott Shaham, Tal Haklay, and 2 more authorsIn The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024Fine-tuning on generalized tasks such as instruction following, code generation, and mathematics has been shown to enhance language models’ performance on a range of tasks. Nevertheless, explanations of how such fine-tuning influences the internal computations in these models remain elusive. We study how fine-tuning affects the internal mechanisms implemented in language models. As a case study, we explore the property of entity tracking, a crucial facet of language comprehension, where models fine-tuned on mathematics have substantial performance gains. We identify the mechanism that enables entity tracking and show that (i) in both the original model and its fine-tuned versions primarily the same circuit implements entity tracking. In fact, the entity tracking circuit of the original model on the fine-tuned versions performs better than the full original model. (ii) The circuits of all the models implement roughly the same functionality: Entity tracking is performed by tracking the position of the correct entity in both the original model and its fine-tuned versions. (iii) Performance boost in the fine-tuned models is primarily attributed to its improved ability to handle the augmented positional information. To uncover these findings, we employ: Patch Patching, DCM, which automatically detects model components responsible for specific semantics, and CMAP, a new approach for patching activations across models to reveal improved mechanisms. Our findings suggest that fine-tuning enhances, rather than fundamentally alters, the mechanistic operation of the model.
@inproceedings{DBLP:conf/iclr/PrakashSHBB24, author = {Prakash, Nikhil and Shaham, Tamar Rott and Haklay, Tal and Belinkov, Yonatan and Bau, David}, title = {Fine-Tuning Enhances Existing Mechanisms: {A} Case Study on Entity Tracking}, booktitle = {The Twelfth International Conference on Learning Representations, {ICLR} 2024, Vienna, Austria, May 7-11, 2024}, publisher = {OpenReview.net}, year = {2024}, url = {https://openreview.net/forum?id=8sKcAWOf2D}, timestamp = {Wed, 07 Aug 2024 17:11:53 +0200}, biburl = {https://dblp.org/rec/conf/iclr/PrakashSHBB24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, } - ICLR - SPOTLIGHT
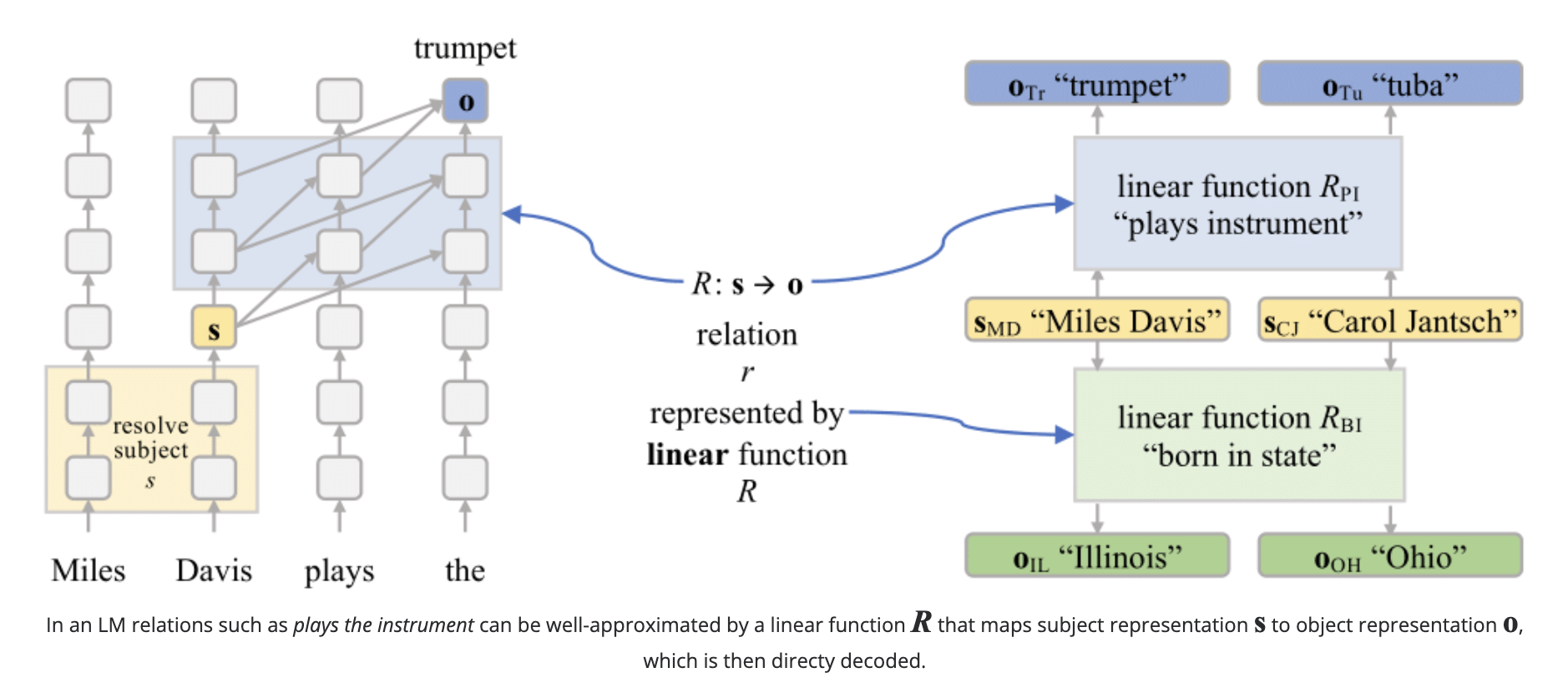 Linearity of Relation Decoding in Transformer Language ModelsEvan Hernandez, Arnab Sen Sharma, Tal Haklay, and 5 more authorsIn The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024spotlight paper
Linearity of Relation Decoding in Transformer Language ModelsEvan Hernandez, Arnab Sen Sharma, Tal Haklay, and 5 more authorsIn The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024, 2024spotlight paperMuch of the knowledge encoded in transformer language models (LMs) may be expressed in terms of relations: relations between words and their synonyms, entities and their attributes, etc. We show that, for a subset of relations, this computation is well-approximated by a single linear transformation on the subject representation. Linear relation representations may be obtained by constructing a first-order approximation to the LM from a single prompt, and they exist for a variety of factual, commonsense, and linguistic relations. However, we also identify many cases in which LM predictions capture relational knowledge accurately, but this knowledge is not linearly encoded in their representations. Our results thus reveal a simple, interpretable, but heterogeneously deployed knowledge representation strategy in transformer LMs.
@inproceedings{DBLP:conf/iclr/HernandezSHMWAB24, author = {Hernandez, Evan and Sharma, Arnab Sen and Haklay, Tal and Meng, Kevin and Wattenberg, Martin and Andreas, Jacob and Belinkov, Yonatan and Bau, David}, title = {Linearity of Relation Decoding in Transformer Language Models}, booktitle = {The Twelfth International Conference on Learning Representations, {ICLR} 2024, Vienna, Austria, May 7-11, 2024}, publisher = {OpenReview.net}, year = {2024}, url = {https://openreview.net/forum?id=w7LU2s14kE}, timestamp = {Mon, 29 Jul 2024 17:17:48 +0200}, biburl = {https://dblp.org/rec/conf/iclr/HernandezSHMWAB24.bib}, bibsource = {dblp computer science bibliography, https://dblp.org}, note = {spotlight paper} }